empirical
exponential
distribution data file
| input_filename-ee.dat |
| theoretical
exponential
distribution data file | input_filename-te.dat |
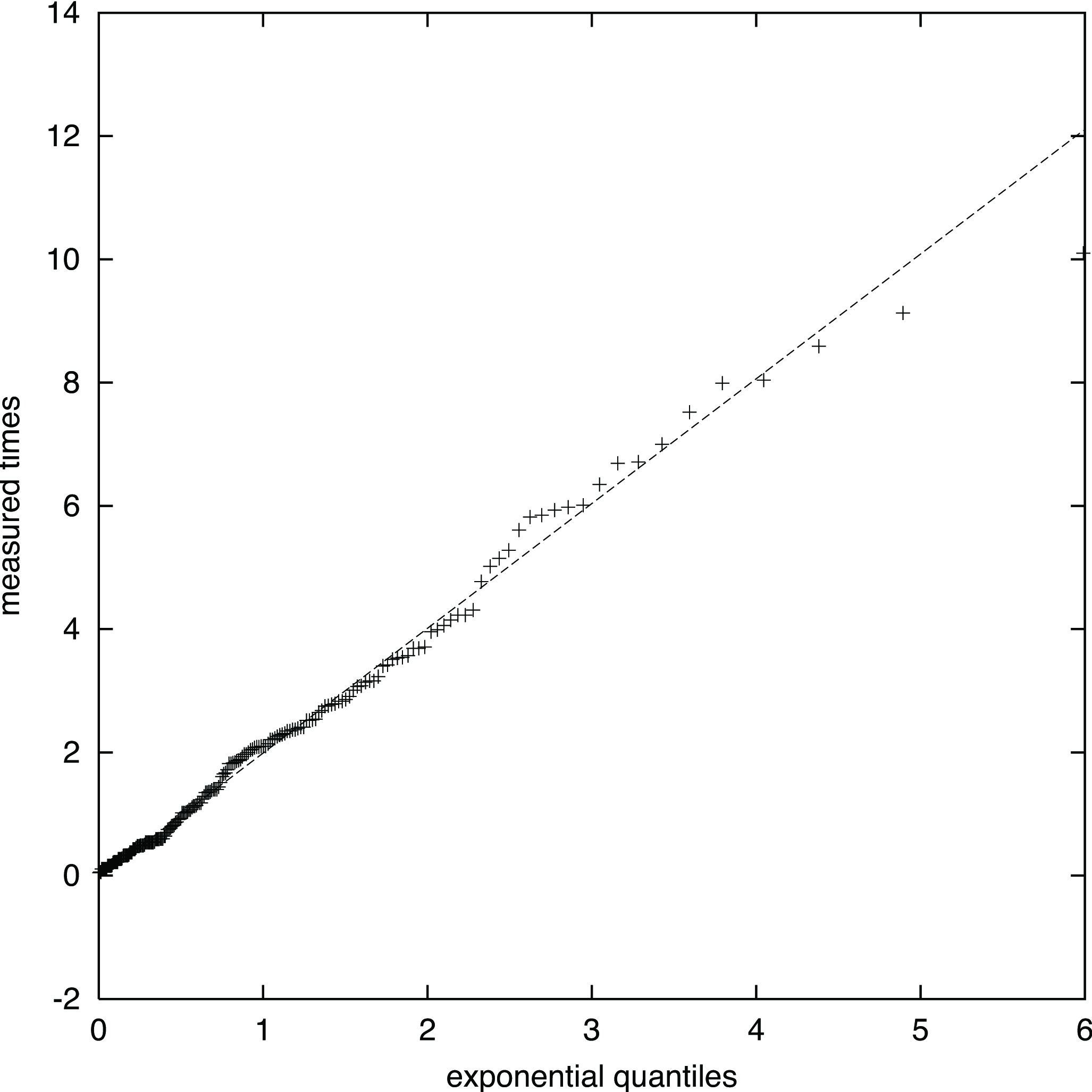
empirical
QQ-plot
data file
| input_filename-el.dat |
theoretical
QQ-plot
data file
| input_filename-tl.dat |
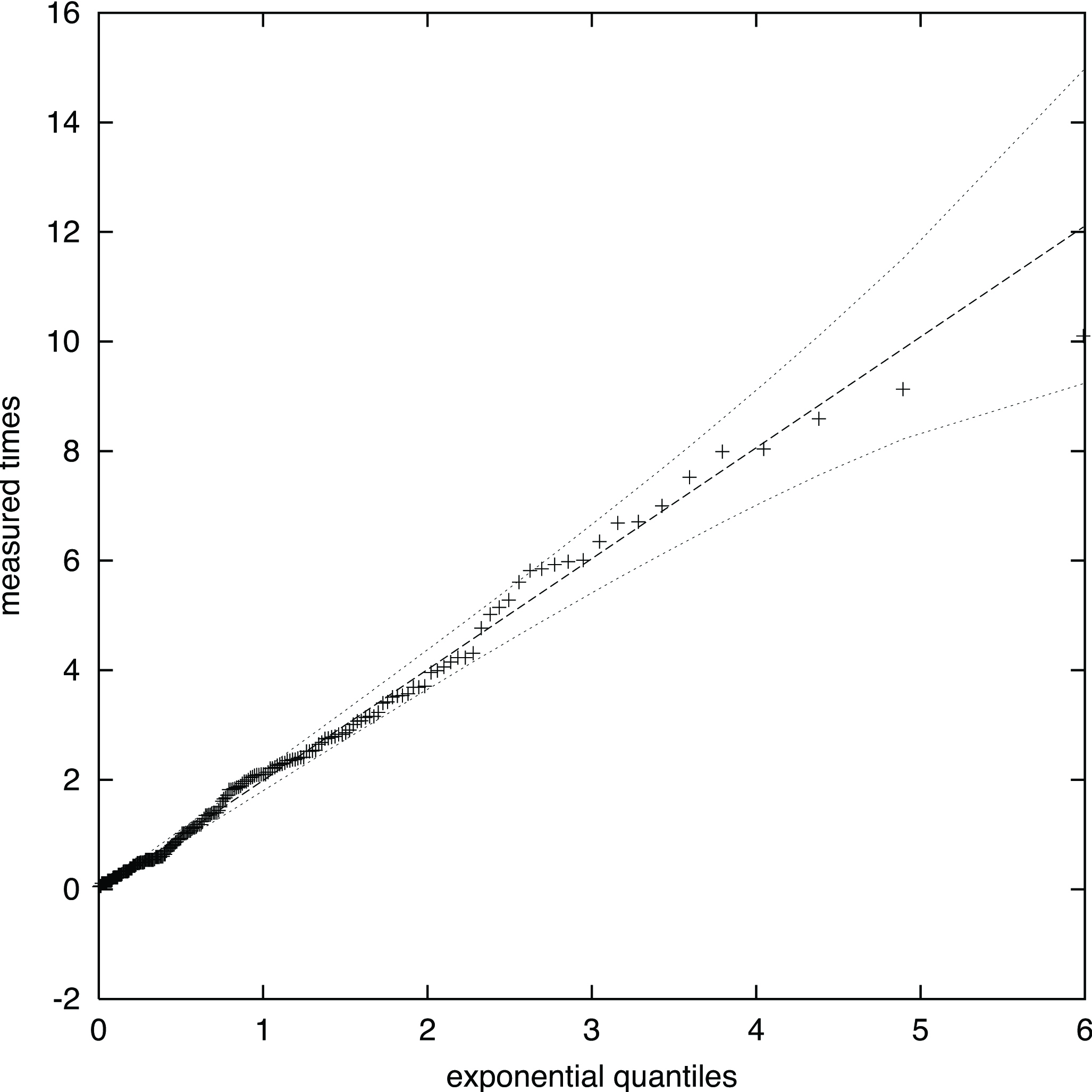
theoretical
upper
1 standard deviation QQ-plot data
| input_filename-ul.dat |
| theoretical
lower
1 standard deviation QQ-plot data | input_filename-ll.dat |
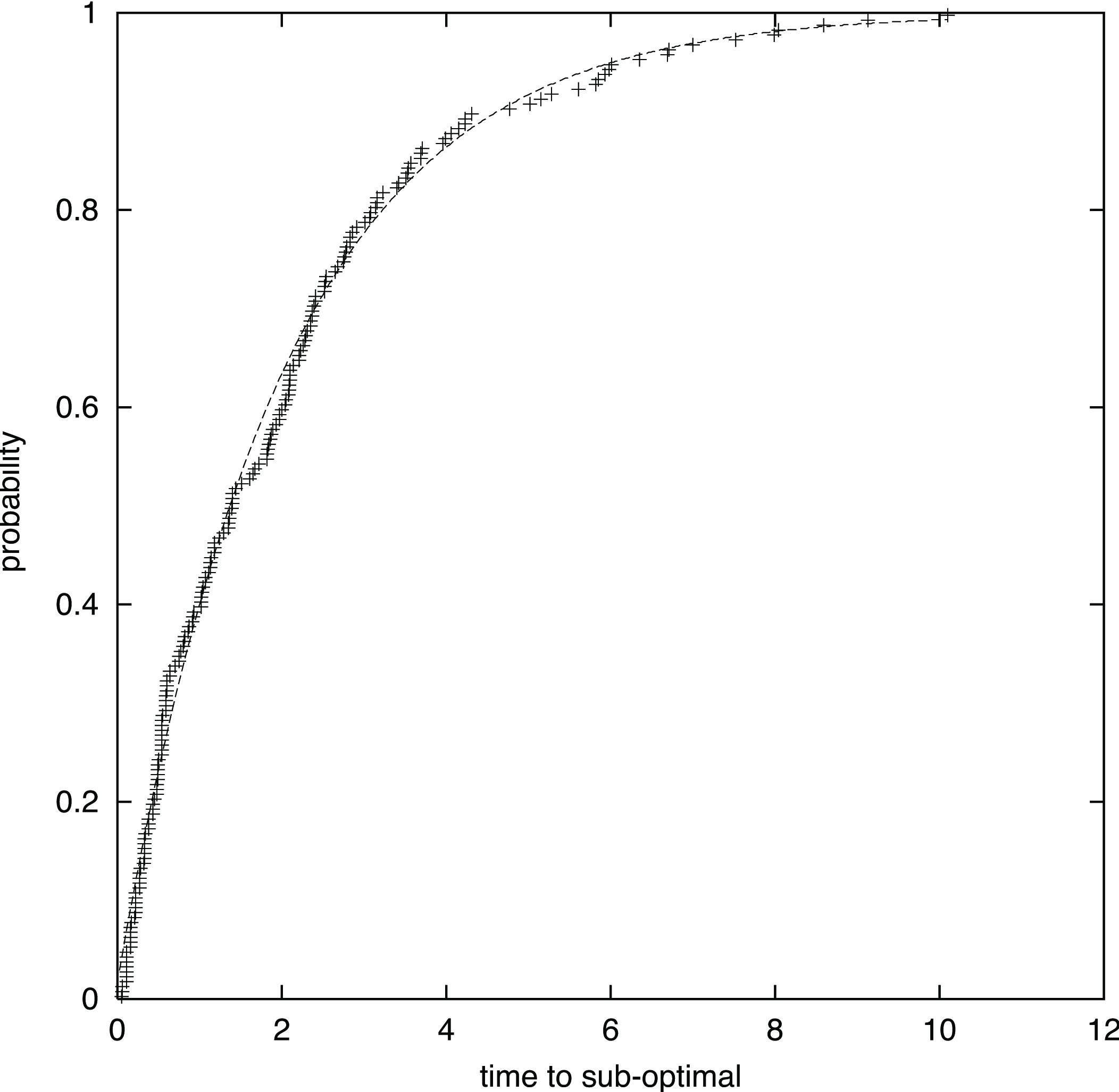
theoretical
vs empirical TTT plot gnuplot file
| input_filename-exp.gpl |
theoretical
vs empirical QQ-plot gnuplot file
| input_filename-qq.gpl |
theoretical
vs empirical TTT plot PostScript file
| input_filename-exp.ps |
theoretical
vs empirical QQ-plot PostScript file
| input_filename-qq.ps |